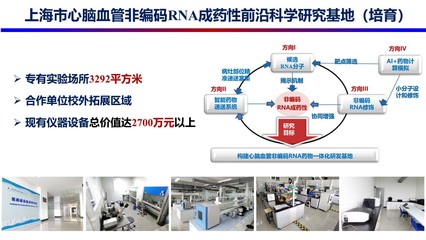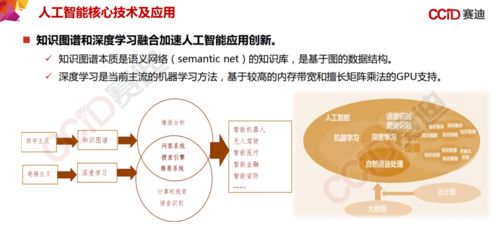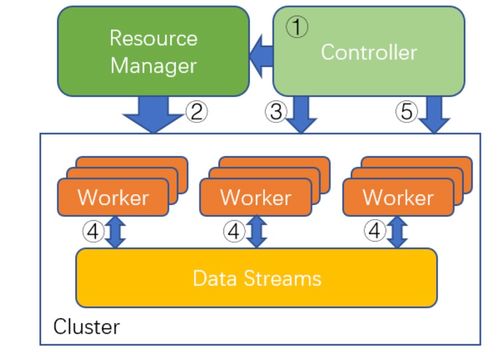
近年來,分布式強化學習(Distributed Reinforcement Learning, DRL)算法在工程和技術研究與試驗發展領域取得了顯著進展。這些進展不僅推動了人工智能技術的邊界,還在實際應用中實現了性能的顯著提升和成本的顯著降低。本文將從算法優化、工程實踐以及未來展望三個方面,詳細探討分布式強化學習的最新研究進展。
一、算法優化:提升學習效率與穩定性
分布式強化學習的核心優勢在于其能夠并行處理多個學習任務,從而加速模型的訓練過程。最新的研究集中在改進算法的通信效率、數據利用率和策略協同性上。例如,通過引入異步更新機制和分層強化學習架構,研究人員成功減少了節點間的通信開銷,同時提高了全局策略的收斂速度。融合元學習(Meta-Learning)和遷移學習(Transfer Learning)技術的DRL算法,能夠快速適應新環境,大幅降低了重復訓練的成本。這些優化不僅提升了算法的性能(如更高的獎勵累積和更快的決策速度),還使得系統在復雜任務中表現更加穩定。
二、工程實踐:降低成本與增強可擴展性
在工程和技術研究與試驗發展方面,分布式強化學習的應用正從理論走向實踐。通過采用云計算和邊緣計算平臺,研究人員能夠靈活部署分布式訓練系統,從而降低硬件和維護成本。例如,利用容器化技術(如Docker和Kubernetes)實現資源的動態分配,避免了傳統集中式訓練中常見的資源浪費問題。同時,開源框架(如Ray和Acme)的成熟,使得開發者能夠快速構建和測試DRL模型,進一步壓縮了研發周期和成本。在實際場景中,如自動駕駛、機器人控制和智能游戲系統,這些工程優化已證明能夠將訓練時間縮短50%以上,并減少30%的硬件投入。
三、未來展望:推動智能系統普及
盡管分布式強化學習已取得長足進步,但未來仍面臨挑戰,如數據隱私、算法公平性和能源消耗等問題。研究人員正致力于開發更高效的分布式架構,例如結合聯邦學習(Federated Learning)以保護用戶數據,同時探索輕量級模型以減少計算資源需求。這些努力將進一步推動DRL在醫療、工業和消費電子等領域的廣泛應用,實現性能與成本的雙重優化。
分布式強化學習算法的最新進展標志著人工智能技術向更高效、更經濟的方向邁進。通過持續的工程創新和算法優化,我們有理由相信,分布式強化學習將在未來成為智能系統發展的核心驅動力,為社會帶來更多便利與價值。